The world ended. Didn’t you get the memo?

Protože hrabání se v seriálech, filmech a knížkách není nikdy dost, minula nás na Digital Humanities projednou hodina strávená trápením se s eRkem a tentokrát jsme se (už hromadně) věnovali, v duchu text-miningu, šikovnému nástroji Voyant-tools. Což je ta pěkná věc, ze které vypadly všechny ty hezké grafy v minulých postech.

Voyant-tools je jednoduše nástroj, do kterého nasypete hromadu textu – v minulých postech komplet LOTR, Hunger games, Harry Potter, ale prohnala jsem tím i Jo Nesba, Avengers, Nolanovy Batmany nebo legendární The Room (nelze se nepodělit o wordcloud) – a voyant-tools to chvíli bude chroupat a pak vám vyhodí spoustu barevně podtrhaných slov, tabulek, wordcloud, nějaké grafy a spoustu klikatých čar. Co s tím?
Pohodlně se usaďte, asi to bude trochu delší povídání. V duchu (ne)trpělivého vyčkávání na devátý únor a s ním příchozí druhou část čtvrté řady Walking dead (Lumpík odpustí moje nadávání na World War Z, aneb oblíbila jsem si zombíky), jsem do voyant-tools nasypala anglické titulky prvních tří sérií. První problém byl stopwords. Prográmek v sobě sice už nějaké má, ale na různá it’s, i’ve, we’d to poněkud nestačí. Tudíž jsem věnovala dobrou hodinku či dvě probírání nejčastějších anglických stopwords. Pokud jde o titulky, kde vadí ještě časování, stopwords se dají použít i na tohle, pokud tedy nechcete časování odstraňovat v eRku či nedejbože ručně (a nebo taky naopak…). Kamarád Excel během chvilky vypotí řadu čísel od 001 až po 999 a ty stačí nakopírovat mezi stopwords. Není to elegantní řešení, ale funguje to rychle a celkem obstojně.
První výrazná povšimnutelná věc je wordcloud. Po aplikování stop-words se i z něj vyhází čísla a vypadá celkem k světu. Do infografik a na různé blbiny trochu použitelnější wordcloud bude, když si z voyant-tools necháme vypsat četnost výskytu jednotlivých slov a ty nasypeme to nástroje Tagul. Pak už stačí jen vybrat dostatečně jednoduchý obrázek k tématu (v minulém postu batman, avengers, hunger games, skyfall a nový, neuvěřitelně tragický man of steel). Podstatně líp to funguje, když je logo v vektor a ne bitmapa, respektive když tam nejsou žádné barevné přechody, a vůbec nejlíp to funguje, když je logo jednoduchý dvojbarevný symbol (viz právě batman nebo hunger games). U Walking dead aspoň nějak takhle: cloud z Tagulu, původní obrázek, a nakonec když se do toho vloží kámoš Photoshop.



 Voyant-tools v hezky jednoduché a přehledné tabulce vypisuje četnost výskytu jednotlivých slov v každém nahraném dokumentu, respektive specifická slova pro daný dokument. Stejně tak vypisuje počet dokumentů v corpusu, počet slov a počet unikátních slov – v corpusu walking dead je těch unikátních 13,207. Najde nejdelší dokument – podle počtu slov (nejukecanější je překvapivě s02e01 s 8,899 slovy), najde nejfrekventovanější slova a slova, která mají obzvlášť specifický graf výskytu. Zkoušela jsem tak zjistit, jak často se ve kterém díle vyskytují hlavní postavy, což je hezky vidět právě na grafu frekvence výskytu slov.
Voyant-tools v hezky jednoduché a přehledné tabulce vypisuje četnost výskytu jednotlivých slov v každém nahraném dokumentu, respektive specifická slova pro daný dokument. Stejně tak vypisuje počet dokumentů v corpusu, počet slov a počet unikátních slov – v corpusu walking dead je těch unikátních 13,207. Najde nejdelší dokument – podle počtu slov (nejukecanější je překvapivě s02e01 s 8,899 slovy), najde nejfrekventovanější slova a slova, která mají obzvlášť specifický graf výskytu. Zkoušela jsem tak zjistit, jak často se ve kterém díle vyskytují hlavní postavy, což je hezky vidět právě na grafu frekvence výskytu slov.

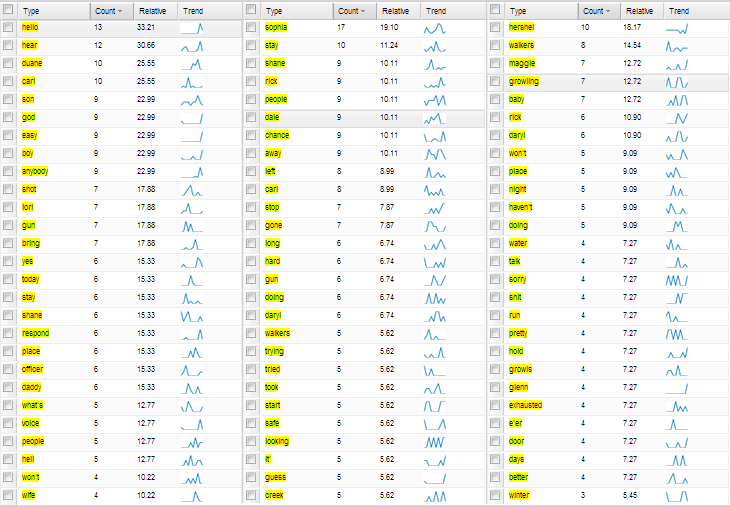 Docela pěkně je tak vidět, kdo nepřežije první sérii, koho v druhé sérii sežerou zombíci a kdo naopak do seriálu postupem času přibude (a kdo taky záhy zase odpadne). Pokud se na seriál teprv chystáte, využijte grafu, ať víte koho si oblíbit, abyste pak nebyli smutní, že ho v druhém dílu sežerou. Obdobně (a trochu složitěji, protože se musí přepínat mezi dokumenty) se pomocí Words in document dá porovnat četnost slov v jednotlivých dílech. Na ukázku jen obrázek, o čem si tak nejvíc povídají v prvních dílech každé série. První série vlevo, druhá uprostřed, třetí vpravo.
Docela pěkně je tak vidět, kdo nepřežije první sérii, koho v druhé sérii sežerou zombíci a kdo naopak do seriálu postupem času přibude (a kdo taky záhy zase odpadne). Pokud se na seriál teprv chystáte, využijte grafu, ať víte koho si oblíbit, abyste pak nebyli smutní, že ho v druhém dílu sežerou. Obdobně (a trochu složitěji, protože se musí přepínat mezi dokumenty) se pomocí Words in document dá porovnat četnost slov v jednotlivých dílech. Na ukázku jen obrázek, o čem si tak nejvíc povídají v prvních dílech každé série. První série vlevo, druhá uprostřed, třetí vpravo.
Úplně stejně jako frekvence funguje i TermsRadio (kliknout! super věc!) které sice nepřináší žádný nový poznatek, zato se na ně pěkně kouká (a přijde mi, že je v tom líp vidět, kde se jaká slova vyskytují). Jednoduše si nakliknete jednu, nebo klidně všechny postavy v grafu a vlevo dole můžete zvolit forward. Plynule si tak přehrajete, v kterých dílech se kdo nejvíc vyskytuje (případně na které díly vůbec nestojí za to koukat).

To samé, jen trochu jinak (a otázka je, jestli přehledněji, každopádně je to barevné, je to graf, je to cool!) zobrazuje Bubblelines. Jednotlivé bubliny jsou frekvence výskytu slova, respektive tady spíš hlavních postav, v jednotlivých dokumentech – dílech – celého corpusu. Velikost bubliny pak udává četnost výskytu – čím častěji, tím je bublina větší.

Links by měly představovat síť propojených slov a výrazů skrz corpus. Jednotlivá slova se liší velikostí podle frekvence jejich výskytu. Jednoduše jde o cosi jako síť přátel na Facebooku generovanou přes Gephi. Velikost slov je jednoduše betweeness, hlavní postavy jsou nejdůležitější a propojují ostatní slova – jsou tedy betweeners. Každá postava má pak kolem sebe skupinu slov, které se ve spojení s nimi nejčastěji vyskytují.
 Další docela zajímavý nástroj, který mě celkem překvapil přesností, je RezoViz, který zobrazuje vztahy mezi lidmi, místy a organizacemi skrze všechny dokumenty v corpusu. Spojení tvoří mezi každým párem lidí, míst nebo organizací, které najde ve stejném dokumentu.
Další docela zajímavý nástroj, který mě celkem překvapil přesností, je RezoViz, který zobrazuje vztahy mezi lidmi, místy a organizacemi skrze všechny dokumenty v corpusu. Spojení tvoří mezi každým párem lidí, míst nebo organizací, které najde ve stejném dokumentu.
 Visualcolocator jednoduše zobrazuje propojení a síť nějak spolu svázaných slov. Tloušťka spojnice mezi slovy pravděpodobně udává jak často se na sebe konkrétní slova vážou.
Visualcolocator jednoduše zobrazuje propojení a síť nějak spolu svázaných slov. Tloušťka spojnice mezi slovy pravděpodobně udává jak často se na sebe konkrétní slova vážou.

Další funkce FeatureClusters vizualizuje vztahy mezi slovy na základě společných prvků setů slov, ve kterých se dané slovo vyskytuje. Jednotlivé nody se spojí, když mají společné stejné sety slov, které se kolem nich vyskytují. To by měla být ta menší kolečka kolem, ale je to beta verze a asi to nefunguje úplně správně, nebo mám cosi špatně s corpusem, protože mi místo společných slov zobrazuje pořád jen nesmyslné řady písmen.

Teď k trochu obskurnějším záležitostem. Naprosto nemám tušení, co má být tohle. Funkce Knots má alespoň podle voant-tools reprezentovat corpus jako shluk zakřivených čar. To by zatím odpovídalo. Každá linka představuje jedno vybrané slovo z corpusu skrze všechny dokumenty, které v corpusu jsou. Rozsah, ve kterém linie překrývají označuje úroveň korespondence nebo propojení jednotlivých slov. Hádám, a to jen velmi matně, že některé postavy (resp. slova) se vyskytují samostatněji, mají víc vlastních scén a nepečou s ostatními postavami – a tím pak vytvoří úplně mimo odbíhající čáru. Použití v tom moc nevidim, ale budiž. Je to docela hezkej barevnej zmatek.
![]() Poslední a úplně nejobskurnější záležitostí je Flowerbed, což by měl být „jednoduchý vizualizační nástroj pro porovnávání dvou dokumentů“. Dokument je prezetován jako záhon, kde každé slovo je květina. Výška květiny určuje relativní četnost slova v dokumentu, okvětní lístky pak vlastnosti se slovem spojené. Údajně se tím dají dokumenty porovnávat, ale žádné kytky mi z toho nerostly a to jsem poctivě prozkoušela všech pětatřicet dílů navzájem. Inu, asi ta betaverze.
Poslední a úplně nejobskurnější záležitostí je Flowerbed, což by měl být „jednoduchý vizualizační nástroj pro porovnávání dvou dokumentů“. Dokument je prezetován jako záhon, kde každé slovo je květina. Výška květiny určuje relativní četnost slova v dokumentu, okvětní lístky pak vlastnosti se slovem spojené. Údajně se tím dají dokumenty porovnávat, ale žádné kytky mi z toho nerostly a to jsem poctivě prozkoušela všech pětatřicet dílů navzájem. Inu, asi ta betaverze.
Bohužel je teď vánoční seriálová pauza, která je po obzvlášť napínavém mid-season finale čtvrté řady Walking dead snad za trest, tak se do dalších podobných srandiček k celé čtvrté řadě pustím až za dva měsíce… nemohl by už být únor?
Posted on 10 prosince, 2013, in Digital Humanities, StuNoMe. Bookmark the permalink. Napsat komentář.

Napsat komentář
Comments 0